前情提要: 昨天稍微提到了模型蒸餾的概念,目的就是為了壓縮模型的大小增加速度。
今天來提提Finetune及一些量化的東西吧。
github參考:
https://github.com/unslothai/unsloth
https://github.com/pytorch/torchtune
https://github.com/huggingface/peft
在torchtune當中有提到Full finetune, LoRA, QLoRA,我們一般的fine-tune通常會對整個模型的參數進行微調,那LoRA跟QLoRA則使用了一些技術,降低微調的成本並且精準度不會差到哪裡去。
蠻多新的fine-tune技術,不只LoRA還有DoRA一些,但比較常看到是LoRA跟QLoRA。
觀念參考:
https://blog.csdn.net/Janexjy/article/details/139709200
https://blog.csdn.net/deephub/article/details/136735670
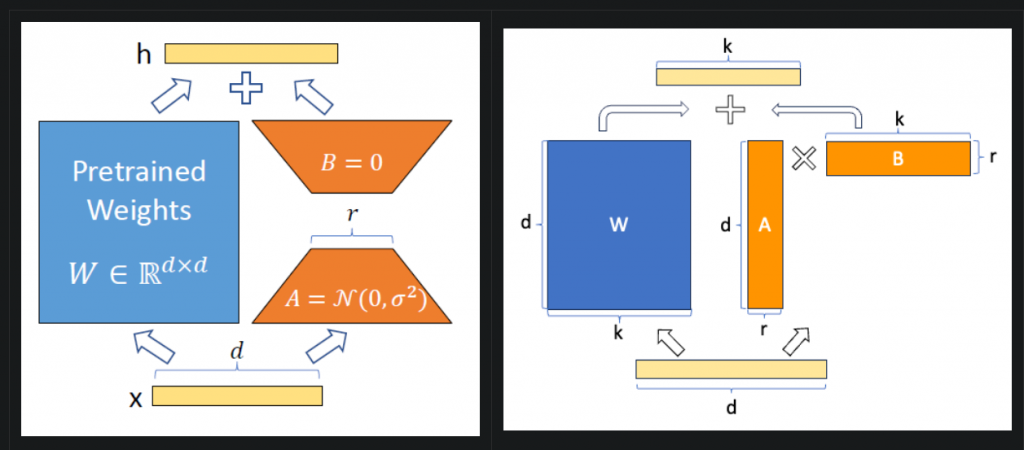
這裡大概敘述LoRA原理,原先模型的全部參數是W,但我們並不更新原先參數,而是多加了A(d x r)跟B(r x k)這兩個矩陣,如果把AB做矩陣相乘,那麼就會得到d x k的大小,就跟原先的W一樣,那我就做相加的動作,進而達到改變原始參數的效果,但因為只多了A跟B兩個的參數其實非常少,所以GPU開銷會低得多,所以常會看到在顯卡24G可以fine-tune LLM,就是用了這類繼續。
觀念參考: https://medium.com/@averyaveavi/%E6%B7%BA%E8%AB%87deeplearning%E7%9A%84%E6%B5%AE%E9%BB%9E%E6%95%B8%E7%B2%BE%E5%BA%A6fp32-fp16-tf32-bf16-%E4%BB%A5llm%E7%82%BA%E4%BE%8B-9bfb475e50be
github參考: https://github.com/Macaronlin/LLaMA3-Quantization
量化也是一個將模型縮小增加速度的方法,他的簡單概念是透過將參數精度轉換,一定常看到float32, float16, bfloat16, int8, int4這些,透過較低的精度來加快模型運算速度,在github上的圖表有一系列的評分,可以參考一下目前使用的方法。
這部分一樣我沒有過多的研究,也沒有去實作,只是提個概念讓碩班知道而已,如果有興趣或研究方向是這個,可以參照上面的github,unsloth或torchrun都算蠻主流的。
今天就先到這裡囉~ 明天就完賽感言了 QQ


 iThome鐵人賽
iThome鐵人賽